Image-to-Voxel Model Translation for 3D Scene Reconstruction and Segmentation
MIPT, Moscow, Russia
In ECCV 2020

Image-to-semantic voxel model translation using our SSZ model. Input color image (left), 2D-to-3D contour alignment (center), semantic voxel model output (right).
Abstract
Object's class, depth, and shape are instantly reconstructed by a human looking at a 2D image. While modern deep models solve each of these challenging tasks separately, they struggle to perform simultaneous scene 3D reconstruction and segmentation. We propose a single shot image-to-semantic voxel model translation framework. We train a generator adversarially against a discriminator that verifies the object’s poses. Furthermore, trapezium-shaped voxels, volumetric residual blocks, and 2D-to-3D skip connections facilitate our model learning explicit reasoning about 3D scene structure. We collected a SemanticVoxels dataset with 116k images, ground-truth semantic voxel models, depth maps, and 6D object poses. Experiments on ShapeNet and our SemanticVoxels datasets demonstrate that our framework achieves and surpasses state-of-the-art in the reconstruction of scenes with multiple non-rigid objects of different classes. We made our model and dataset publicly available.
Semanticvoxels Dataset
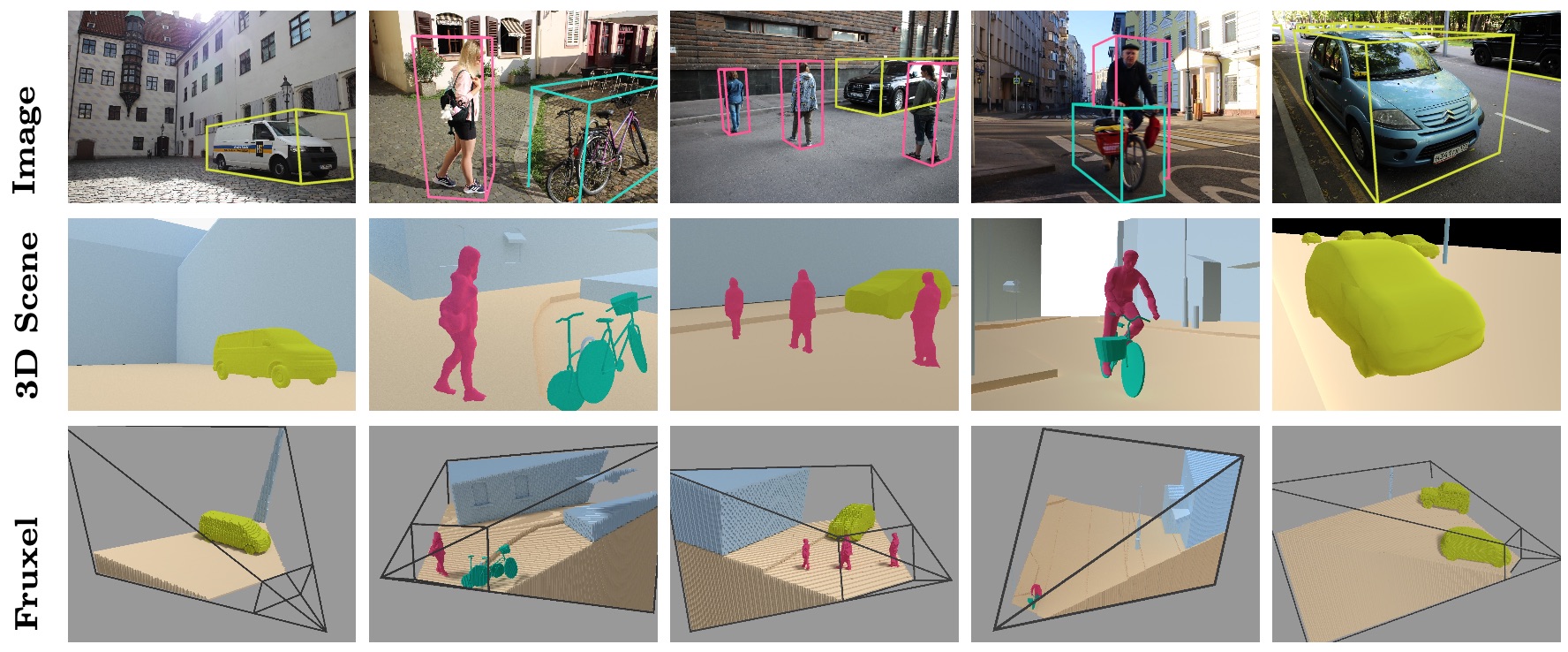
SemanticVoxels Dataset poster.
Our SemanticVoxels dataset includes 116k samples of 3D and 2D data. Each data sample represents a single camera pose. It includes a color image, a semantic frustum voxel model, a depth map, a camera pose, and an object pose annotations for all classes: person, car, truck, van, bus, building, tree, bicycle, ground.
For download "SemanticVoxels Dataset" dataset write to vl.kniaz@gosniias.ru
Created date: 2022-10-13 09:58:58
Last update: 2022-10-13 09:58:58